Utiliser des onglets dans l’éditeur Vim – ouvrir un shell
Je souhaite partager un usage de Vim très intéressant: pouvoir travailler dans Vim avec des onglets et dans chaque onglet des fichiers différents et/ou même plusieurs fenêtres dans chaque onglet.
Bon, c’est le quatrième billet sur le sujet, si vous découvrez Vim, commencez par lire « VIM 01 – Entrer et sortir de Vim et Vimtutor » et surtout suivez le tutoriel « Vimtutor ».
Commencez par ouvrir plusieurs fichiers dans Vim avec la commande:
$ vim -p fichier1 fichier2 fichier3
Ce que dit le « man vim » concernant l’option « -p »
-p[N] Ouvre N onglets. Quand N est omis, ouvre un onglet pour chaque fichier fichier.
Les trois fichiers ont été ouverts dans Vim sur des onglets différents.
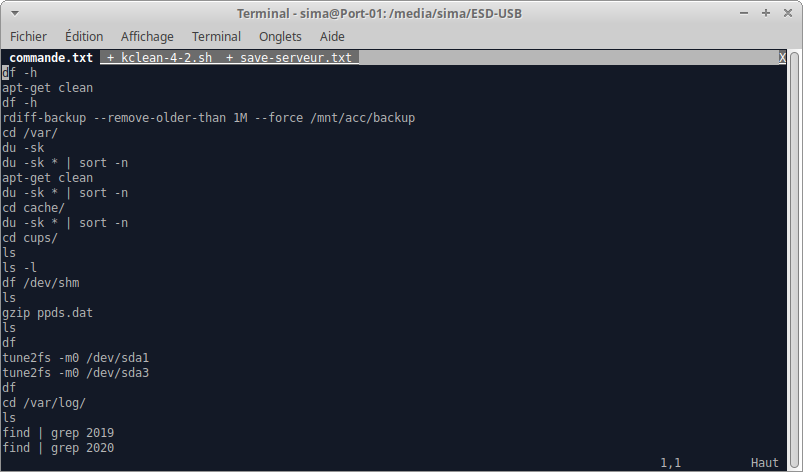
Si vous voulez en ouvrir un autre, il suffit de taper la commande
:tabnew fichier4
Et un nouvel onglet s’ouvrira.
Il y a aussi d’autres options pour ouvrir les onglets à différents endroits:
:-tabnew → ouvre l'onglet avant l'onglet actuel :0tabnew → ouvre l'onglet en première position :$tabnew → ouvre l'onglet en dernière position
Dans la partie supérieure l’on voit les différents onglets ouverts et le nom du fichier. Si vous modifiez le texte d’un onglet, le signe + apparaît à côté de son nom pour indiquer qu’il a été modifié et non sauvegardé.
Si vous divisez « Splitter » un onglet (comme vu dans Vim-03), un numéro apparaît à côté du nom, indiquant le nombre de divisions de cet onglet
Pour se déplacer entre les différents onglets, plusieurs options. En mode normal:
gt → passe à l'onglet suivant gT → passe à l'onglet précédent :tabfirst → passe au premier onglet :tablast → passe au dernier onglet
Il y a aussi la possibilité de pouvoir réorganiser les onglets existants de la manière que vous souhaitez. Pour ce faire, il y a la commande « :tabm n » où « n » est le numéro de la position où l’on veut déplacer l’onglet en cours, en tenant compte du fait qu’il commence à compter à partir de la position 0.
Mettre l’onglet actuel en première position, nous tapez:
:tabm 0
Si vous voulez voir les onglets que vous avez ouverts et ce que vous avez dans chacun d’entre eux, vous pouvez exécuter la commande
:tabs
Exemple:
$ vim -p work/arch-vim/vim-03/vim-todo-lists.vim todo.vim Documents-vim.todo-list.txt
Dans Vim tapez « :tabs »
:tabs
Résultat:
Onglet 1 > work/arch-vim/vim-03/vim-todo-lists.vim Onglet 2 todo.vim Onglet 3 Documents-vim.todo-list.txt Appuyez sur ENTRÉE ou tapez une commande pour continuer
Cela nous indique que je suis actuellement sur l’onglet 1 « > » et le nom de fichier ouvert dans chaque onglet.
J’en ai fini avec les onglets, passons à l’ouverture d’un Shell
Ouvrir un shell depuis Vim
Vous êtes sur vim, et soudain, vous avez besoin de vérifier une ligne de commande ou autre chose depuis un terminal.
Inutile d’ouvrir un autre terminal, ou un onglet terminal (ne pas confondre avec onglet Vim vu plus haut), ou quitter Vim pour y revenir….
Rien de plus simple que d’ouvrir un shell depuis Vim.
Tapez l’une de ces deux commandes :
:shell
ou simplement:
:sh
Pour quitter le shell et revenir à notre vim, tapez
exit
Rajout suite aux commentaires 2020-0622-22:02.
On peut visualiser le shell en faisant:
:!
Appuyer sur « Entrée » pour revenir à Vim
Ou encore accéder au shell en tapant Ctrl+z pour passer Vim en arrière plan, faites ce que vous avez à faire, puis exécutez « fg » pour faire revenir Vim au premier plan.
Fin de rajout
Application Vim sur le tag Vim