De temps en temps, quand ils s’ennuient à espionner, l’« intelligence agency » les agences de renseignements des États-Unis nous permettent de jeter un œil à certains de leurs jouets. Par exemple, le logiciel Ghidra, qui peut intéresser des experts en « reverse engineering » Rétro-Ingénierie et sécurité informatique.
Logo de Ghildra
Écrit en langage de programmation Java, il est distribué, sous forme incomplète mais sous licence libre Apache 2.0. De plus il est gratuit, ce qui en fait une alternative intéressante à IDA Pro, un programme fermé et pas vraiment bon marché.
Développée de manière réservée depuis de nombreuses années, il a été montré au public pour la première fois lors de la conférence RSA qui s’est tenue à San Francisco.
Un logiciel capable d’analyser des fichiers binaires (par exemple des logiciels malveillants) inversant le processus de compilation, vers pseudo-code C, permettant aux analystes de comprendre la fonctionnalité de celui-ci.
Il est multi-plateforme (Linux, MacOos, Windows), et compatible avec des logiciels destinés à tous les types de processeurs et de multiples architectures (environ une douzaine). Également extensible dans ses fonctions à base de plugins, à la fois Python et Java, que l’utilisateur peut créer lui-même.
Il se caractérise par ses nombreuses possibilités : effectuer un travail collaboratif, assembleur/dés-assembleur, mode interactif ou automatique, graphiques et diagrammes de flux, raccourcis clavier avancés, possibilité d’annuler les changements. Plus d’une centaine de fonctions différentes et beaucoup à explorer dans cet outil.
Comme toujours, il est conseillé un minimum de précaution dans l’exécution du code de la NSA. Bien qu’ils jurent qu’il n’y a pas de backdoor (porte dérobée) dans The Register, ils ont déjà fait écho à un bug qui, en mode débogueur, permet à Ghidra de se connecter à d’autres systèmes de son réseau et d’exécuter du code.
Voyez les photos d’écran plus bas…
Pour l’exécuter, il faut avoir Java runtime.
Une fois Ghidra installé, pour le lancer :
./ghidra_run
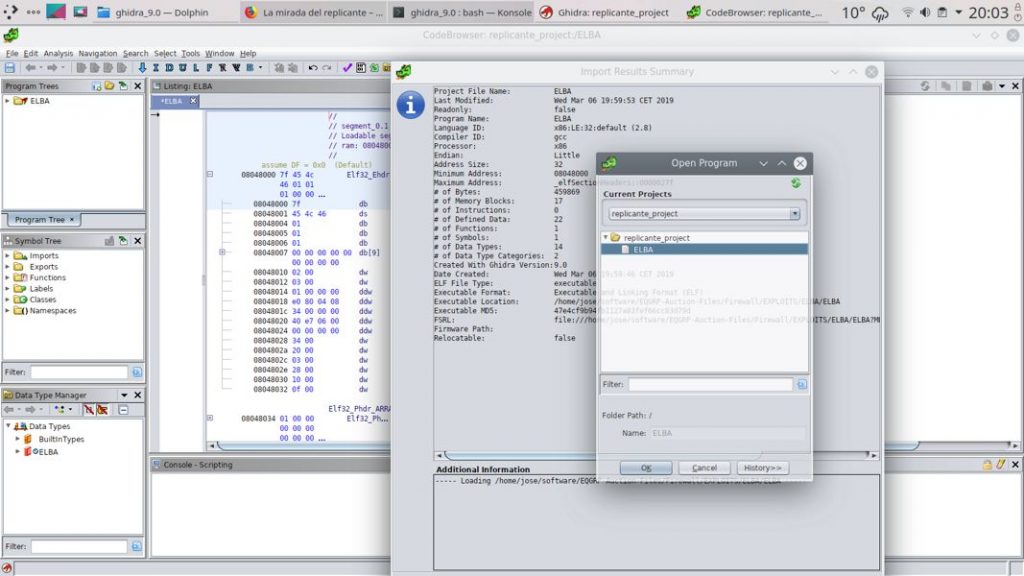
Ghidra, l’outil de reverse engineering de la NSA, présente son accord utilisateur sous licence Apache 2.0, insistant sur la responsabilité de l’utilisateur dans l’usage légal du logiciel.La page d’accueil du guide utilisateur de Ghidra présente les bases de l’outil, son public cible et les limites de la documentation fournie, soulignant son extensibilité via des plugins.L’interface de Ghidra s’ouvre sur une page indiquant qu’aucun projet n’est actif, avec des outils de gestion de projet désactivés et une liste vide d’outils disponibles.Ghidra, l’outil de reverse engineering de la NSA, affiche un projet en cours : ELBA, avec ses structures de programme, ses symboles et ses types de données, ainsi qu’une vue détaillée du code et un résumé des résultats d’import.
Connexion lente, testez les résolveurs DNS – NameBench
Avant tout, la différence entre « Résolveur » (ou serveur récursif) et Serveur faisant autorité (serveur DNS) !
On parle souvent de serveur DNS à tort car il s’agit souvent et surtout dans le cas NameBench de serveurs récursifs.
Résolveur (ou serveur récursif) : serveur DNS qui ne connaît rien mais pose des questions aux serveurs faisant autorité et mémorise les réponses. Chez le FAI, ou sur le réseau local ou serveurs récursifs publics (Quad9, OpenDNS, Google, etc.).
Serveur faisant autorité : serveur DNS qui connaît le contenu d’un domaine. Exemple : les serveurs de l’AFNIC qui connaissent ce qu’il y a dans « .fr » et peuvent répondre. Ou les serveurs de gouvernement.fr chez Gandi et autres…
Pour approfondir vos connaissances sur le sujet allez sur le blog de Stéphane Bortzmeyer que je remercie.
Bon, revenons-en à nos moutons !…
Je suis parmi les utilisateurs les plus distants de mon FAI, ce qui a pour conséquence une connexion internet dont les utilisateurs de modems n’ont rien à m’envier.
Dans ce cas, plus qu’ailleurs, le temps de réponse d’un résolveur DNS a son importance.
Trouver le plus rapide, c’est ce que fait NameBench en testant la rapidité des serveurs récursifs, pour cela il va utiliser l’historique du navigateur et va parcourir les résolveurs DNS locaux et globaux (publics). Il vous signalera également les résolveurs DNS menteurs.
Il est dans les dépôts Debian, une fois installé il suffit le lancer par la commande
$ namebench
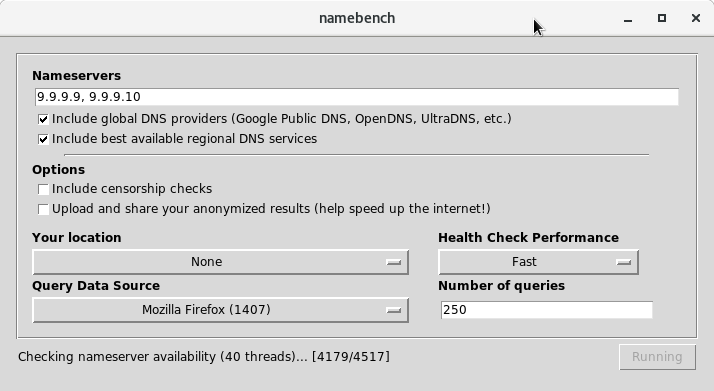
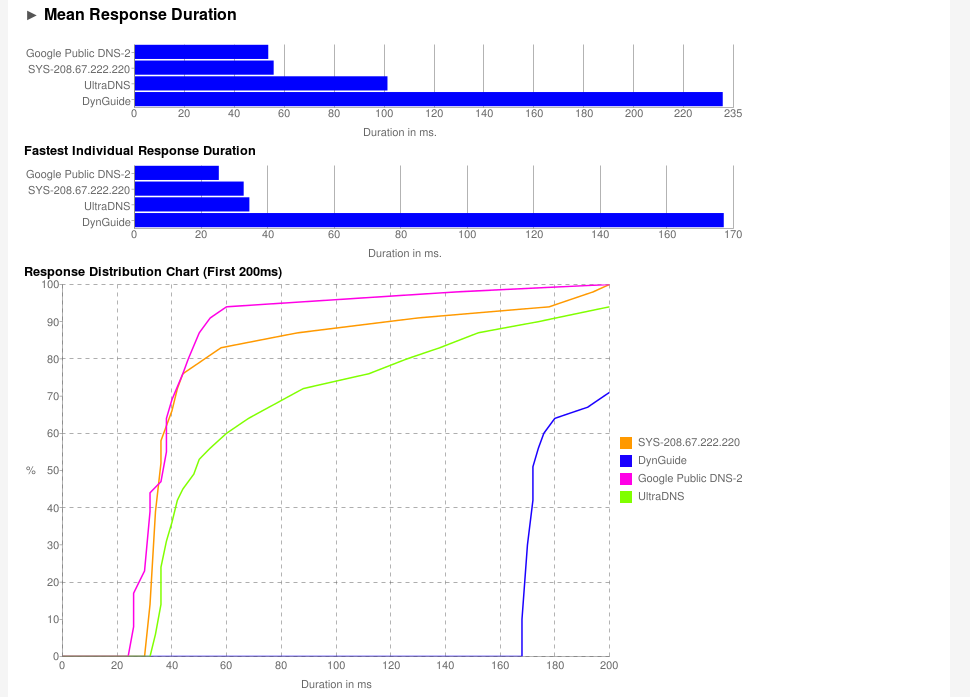
Vous avez l’interface ci-dessous, on peut voir que j’ai comme résolveur DNS 9.9.9.9 et 9.9.9.10 de Quad9
L’interface de Namebench, un outil conçu pour tester et classer les serveurs DNS en fonction de leur vitesse, de leur fiabilité et de leur capacité à contourner la censure.
Cliquez sur test ou running.
C’est parti ! Vous pouvez aller vous faire chauffer un thé, chercher le pain à la boulangerie cela va prendre un certain temps !
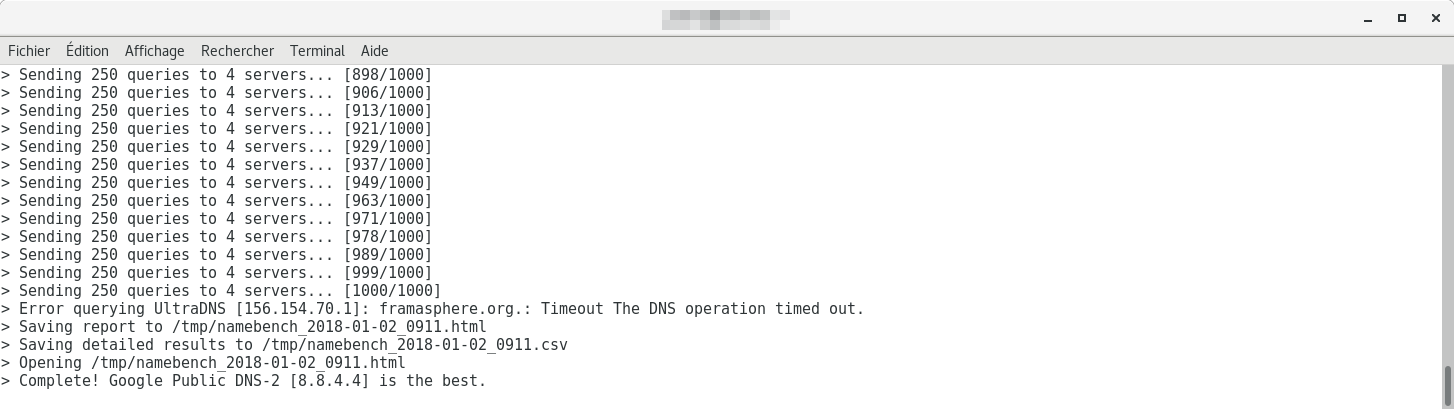
Exemple de sortie de Namebench, un outil qui teste la réactivité de plusieurs serveurs DNS en envoyant des milliers de requêtes. Ici, Google Public DNS-2 (8.8.4.4) est identifié comme le plus efficace.
A la fin vous avez les résultats qui s’affiche sur votre navigateur.
Analyse Namebench révélant que Google Public DNS-2 offre des performances supérieures de 38,4 %, avec une configuration optimale pour améliorer votre connexion internet.
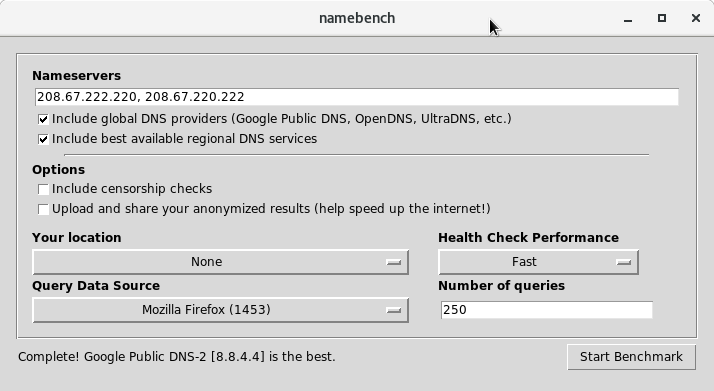
J’ai fait le choix de refaire un test avec les résolveur DNS 208.67.222.220 et 208.67.220.222 de OpenDNS.
Choix que j’ai gardé, même si celui de Google est un poil de cul plus rapide. J’ai plus confiance à OpenDNS qu’en Google.
S’en suit une série de screenshots.
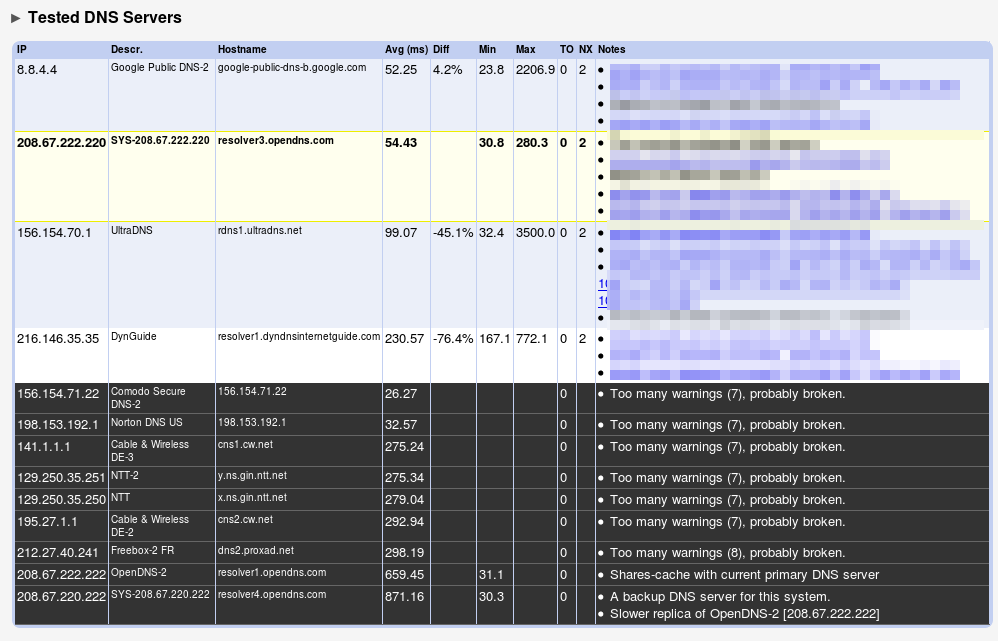
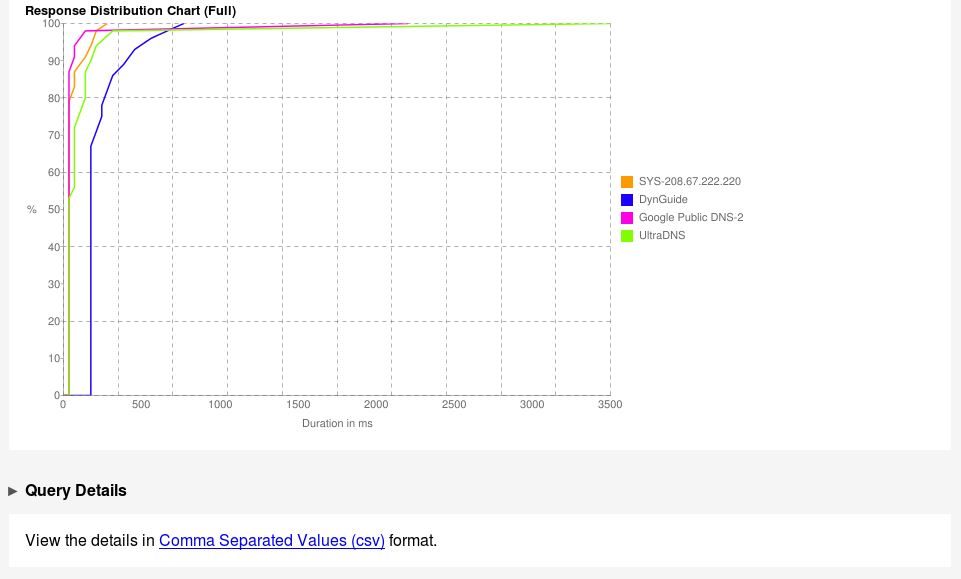
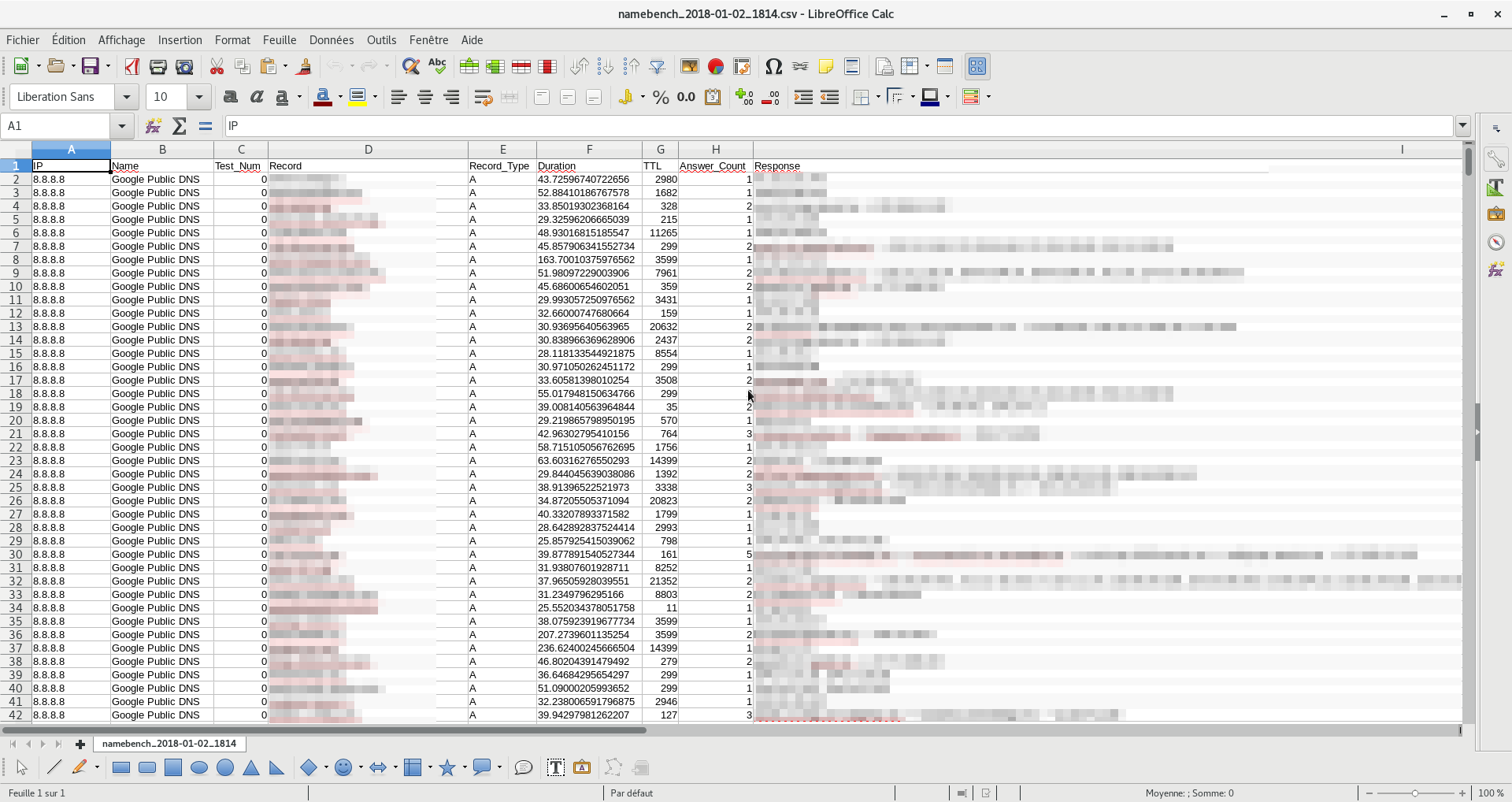
nterface de Namebench permettant de configurer et de lancer des tests de performance sur différents serveurs DNS.Recommandation NameBenchNamebench affiche les résultats de test pour plusieurs serveurs DNS, avec des métriques comme le temps de réponse (Avg ms), les erreurs (TO, NX) et des notes sur leur fiabilité.Namebench présente les temps de réponse moyens et individuels des serveurs DNS, ainsi qu’une courbe de distribution pour évaluer leur réactivité globale.Ce graphique montre la distribution des temps de réponse des serveurs DNS analysés. Les courbes représentent le pourcentage cumulé de réponses en fonction du temps de réponse (en ms).Cette image montre un extrait du fichier CSV « namebench_2018-01-02_1814.csv » ouvert dans LibreOffice Calc. Le tableau contient des informations sur les tests DNS, incluant des colonnes comme l’adresse IP, le type de test, le type d’enregistrement, la durée, le TTL, le nombre de réponses et la réponse elle-même.
Schéma simplifié d’une requête DNS
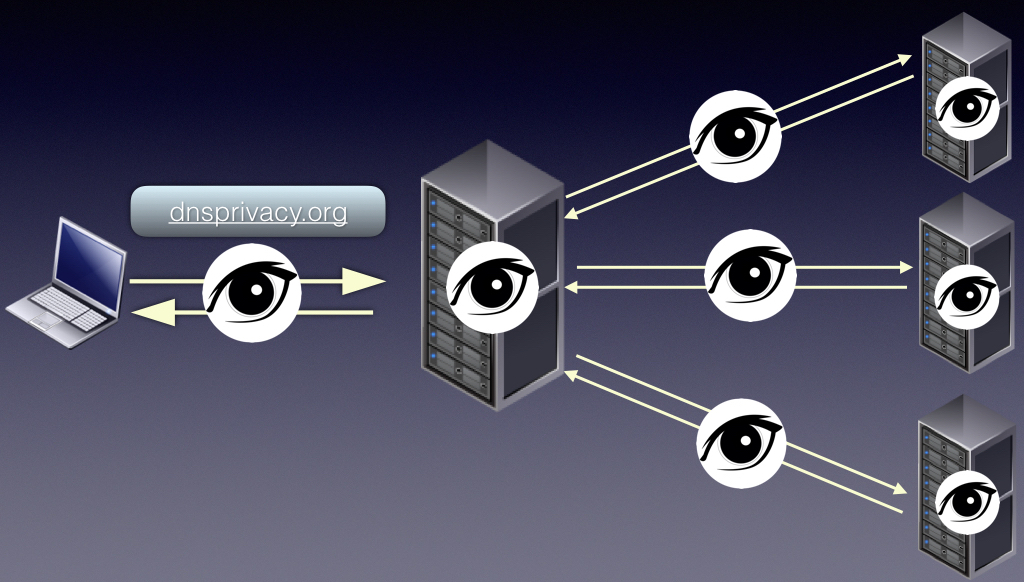
Comment les connexions DNS chiffrées (DoH/DoT) protègent vos données contre les regards indiscrets, avec des appareils connectés à un serveur DNS sécurisé via dnsprivacy.org.
VM VirtualBox est un logiciel libre et open source de virtualisation publié par Oracle. Bien entendu il est disponible pour GNU/Linux mais aussi pour Windows.
Par défaut, les packages de VM VirtualBox ne sont pas disponibles dans les dépôts de paquets de la Debian 9 (nom de code « Stretch« ).
Nous allons donc voir comment installer la dernière version de Oracle VM Virtualbox sur debian.
Allez déjà faire un tour du côté d’Oracle pour connaître quelle est la dernière version de VM Virtualbox. À ce stade, en cliquant sur l’onglet « Downloads » vous pouvez voir les différents « paquets ou sources » au téléchargement proposés aux diverses distributions et systèmes d’exploitations.
Mais si on souhaite avoir un suivi des mises-à-jour… Sous linux il nous suffit de configurer les dépôts, pour Debian c’est là… Voyons comment faire :
Rappel : $=User #=Root
Étape 1 : Ajout du dépôt VM VirtualBox
Ouvrez le terminal et exécutez la commande suivante pour ajouter le dépôt.
Étape 3 : Installez VirtualBox avec la commande apt-get
# apt-get update
# apt-get install virtualbox
La version n’étant pas spécifiée vous aurez un message comme ci-dessous
Le paquet virtualbox est un paquet virtuel fourni par :
virtualbox-5.2 5.2.2-119230~Debian~stretch
virtualbox-5.1 5.1.30-118389~Debian~stretch
virtualbox-5.0 5.0.40-115130~Debian~stretch
Vous devez explicitement sélectionner un paquet à installer.
E: Le paquet « virtualbox » n'a pas de version susceptible d'être installée
C’est le moment de choisir la dernière version…
# apt-get install virtualbox-5.2 5.2.2
Une fois l’installation terminée, essayez maintenant d’y accéder.
Accéder à VirtualBox
Cette capture montre l’interface de recherche du système d’exploitation, où l’utilisateur a saisi « vm virtualbox ». L’icône de VirtualBox est visible dans les résultats, indiquant que l’application est installée et prête à être lancée.
Cliquez sur l’icône de la VM VirtualBox
Cette capture montre l’interface principale de VirtualBox, où aucun machine virtuelle n’a encore été créée. Un message de bienvenue guide l’utilisateur pour créer sa première machine virtuelle en utilisant le bouton « Nouvelle ».
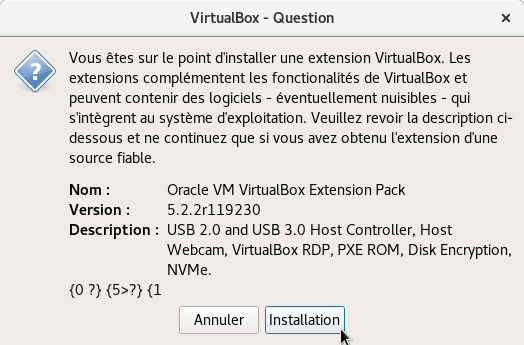
Installer le pack d’extension VirtualBox
Il est recommandé d’installer le module d’extension après l’installation de la VirtualBox. Pour installer le pack d’extension VirtualBox 5.2, nous devons d’abord télécharger le fichier du pack d’extension en utilisant la commande wget suivante :
Pour être certain de bien charger la bonne extension pack, vérifiez ici.
Une fois le fichier téléchargé, accédez à l’interface graphique de VirtualBox et allez sur: Fichier -> Paramètres -> Extensions et sélectionnez le fichier ‘vbox-extpack’ Puis cliquez sur Installer (voir série de screenshots)
Cette capture montre l’onglet « Extensions » dans les préférences de VirtualBox. Aucun paquet d’extension n’est installé ou activé, comme indiqué par la liste vide sous « Paquets d’extension ».Cette capture montre la fenêtre de sélection de fichier pour ajouter une extension à VirtualBox. Le fichier Oracle_VM_VirtualBox_Extension_Pack-5.2.22-119230.vbox-extpack est mis en surbrillance dans le dossier Téléchargements, prêt à être installé.Cette capture montre la fenêtre de licence d’Oracle VM VirtualBox. L’utilisateur est invité à accepter les termes et conditions pour continuer l’installation ou l’utilisation du logiciel.Cette capture montre une fenêtre d’avertissement de VirtualBox qui informe l’utilisateur des risques potentiels liés à l’installation d’une extension. Elle détaille le nom, la version et les fonctionnalités de l’extension Oracle VM VirtualBox Extension Pack.
Il y a une dernière fenêtre, dont j’ai oublié de faire le screenshot, qui nous indique que le pack d’extension a été installé avec succès.
C’est fini pour ce tutoriel, j’espère que vous avez une idée sur la façon d’installer VM VirtualBox et son extension sur Debian (et autres distributions linux).
En espérant vous avoir été utile et n’hésitez pas à me faire savoir comment faire mieux ou si j’ai commis des coquilles…
Votre enfant fait partie de la chorale de la maternelle et le son est sur le site de votre mairie.
Mais, impossible de le télécharger, le site est fait en sorte qu’aucun de vos plugins Firefox fonctionnent et aucun fichier mis à disposition au téléchargement… Mais merde! flûte! C’est la voix de votre enfant dont vous voulez garder une trace!
On se calme, si le son sort de la carte son, c’est qu’il y a moyen de le récupérer.
Ma méthode:
Pavucontrol et AudaCity
Il vous faut deux applications « Pavucontrol » et une application capable d’enregistrer, il y en a plein sous linux, moi j’utilise « Audacity« .
si vous ne les avez pas, installez-les (pour Debian et dérivés ».
# apt-get install pavucontrol audacity
Lancez « Pavucontrol », puis « Audacity ».
Personnellement, je n’ai pas eu besoin d’intervenir dans les configurations, tout est par défaut.
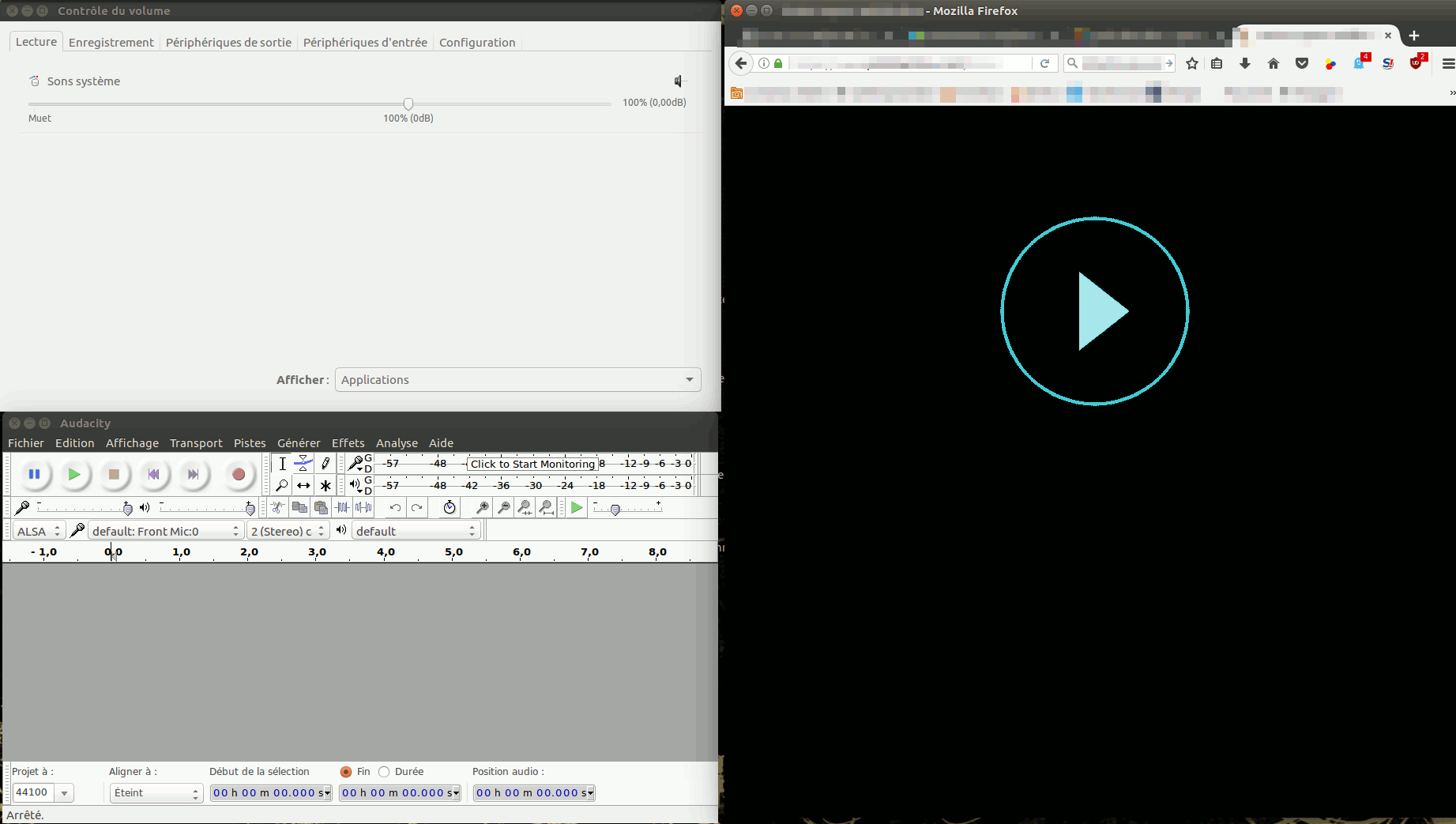
Agencez vos fenêtres de façon à être efficace dans les clics… Image ci-dessous.
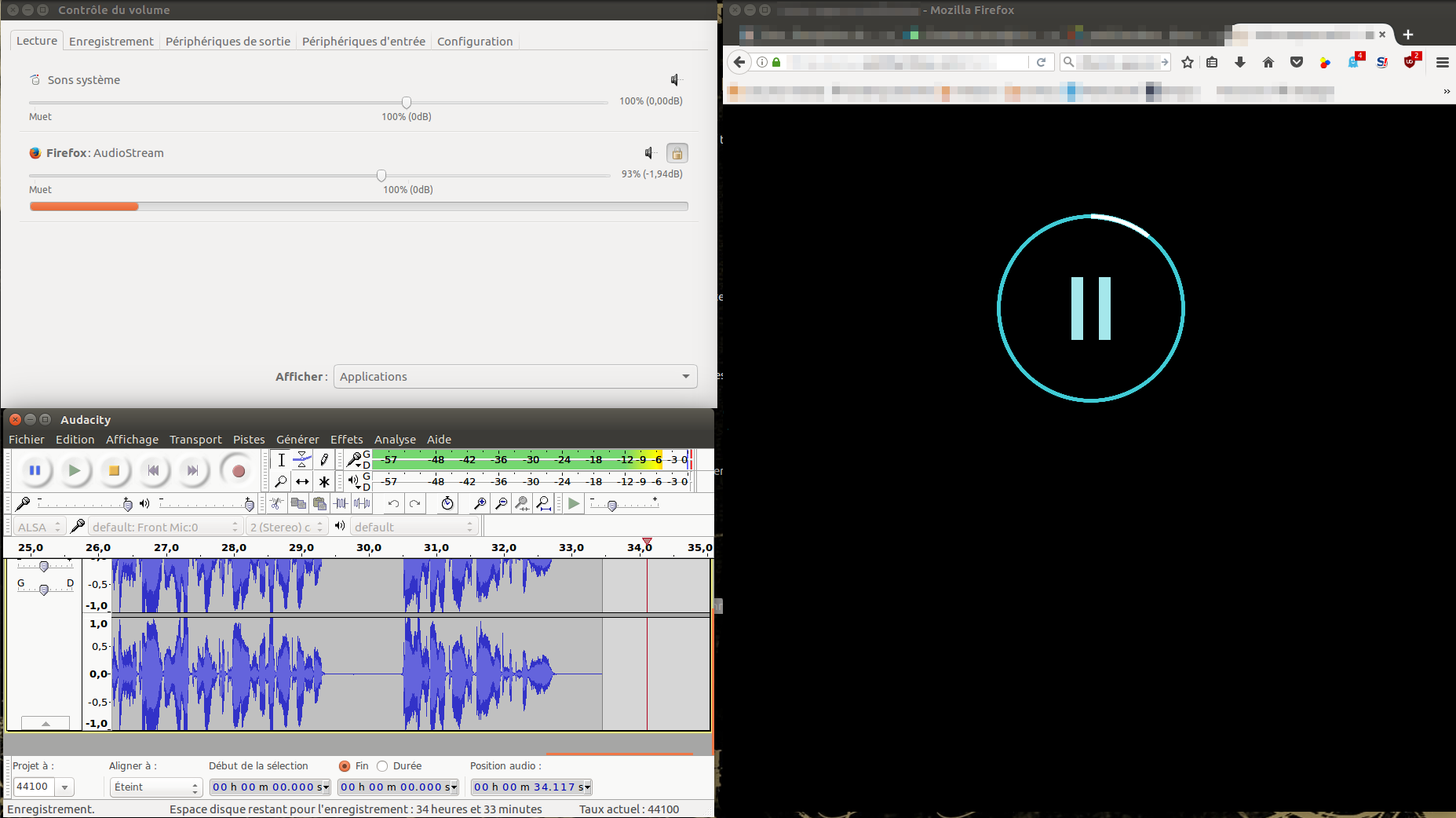
Configuration typique sous Linux pour enregistrer le son d’une vidéo web avec Audacity via PulseAudio.
Lorsque vous lancez la lecture sur votre navigateur, puis enregistrement sur Audicity, vous devriez avoir quelque chose du même genre que ci-dessous.
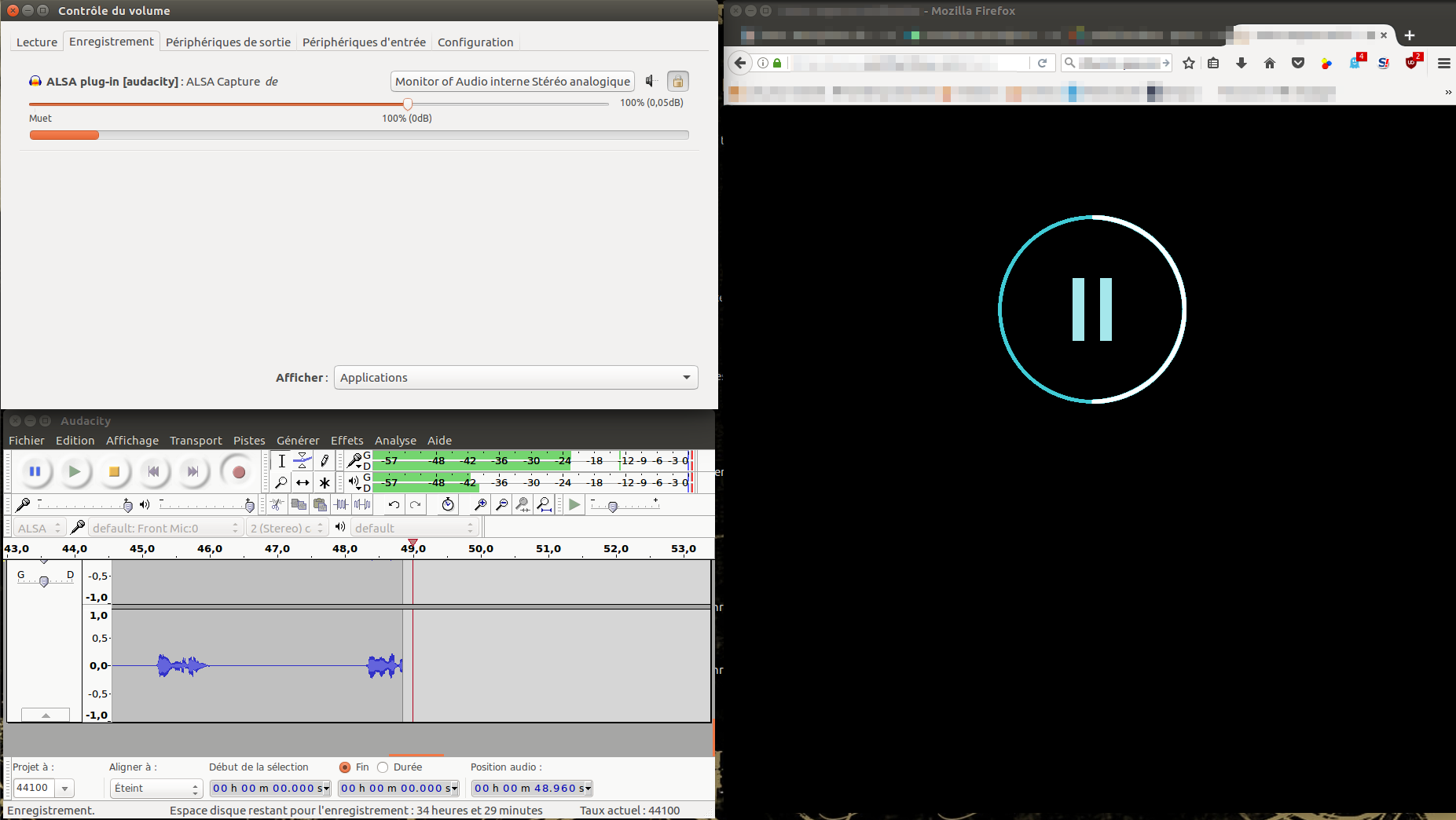
Source d’enregistrement : Audacity capture le moniteur stéréo analogique au lieu du flux Firefox.
Positionnez-vous sur l’onglet « Enregistrement » du contrôle du volume et vous devriez avoir quelque chose du même genre que l’image ci-dessous.
Il faut que ALSA plug-in soit sur « Monitor of Audio interne Stéréo analogique »
Enregistrement audio en cours — Audacity, PulseAudio et Firefox sous Linux
Vous êtes prêt! Alors repartez de zéro, agencez vos fenêtres, puis lancez le fichier son (ou vidéo dont vous voulez récupérer le son) depuis votre navigateur, cliquez sur enregistrer de votre enregistreur (ici Audacity) et il n’y a plus qu’à attendre la fin où vous stopperez votre enregistrement. Faites exporter ou enregistrer en fonction du format souhaité et c’est fini!
Il y a sans doute plein d’autres méthodes n’hésitez pas à les faire connaître.
Alors bien entendu comme je l’avais dit dans un billet précédent, il suffit d’utiliser Geneweb comme un site lambda avec un script cgi…
Sauf que moi je ne souhaite pas l’utiliser ainsi mais en service, via un port dédié.
J’ai donc sur le sujet fait un tutoriel, je l’ai proposé sur une liste de diffusion (mailling list) dédiée à Geneweb. On m’a proposé de le publier sur le site dédié.
Henri G. l’a mis en forme, publié sur le site de geneweb, il en a fait aussi la traduction en anglais, et mis un petit lien de renvoie en fin d’article qui me touche beaucoup.
Un mois plus tard JM fait également une proposition différente de la mienne sur la mailling list, et que je trouve aussi très intéressante.
Il ne s’agit pas d’un tutoriel car je n’ai pas testé, et je n’ai pas envie de modifier la configuration de mon serveur pour tester.
Je le mets pour ceux qui souhaitent tester, creuser, perfectionner, et aussi en pense bête, pour le tester moi-même un jour.
C’est basé sur des certificats auto-signés, ceux qui ont d’autres certificats sauront l’adapter.
La proposition.
JM :(…) un vhost en reverse proxy, comme ça Geneweb n’écoute qu’en local. Ici une vieille configuration éprouvée, pas à jour des dernières modes de Let’s Encrypt & co mais ça donne l’idée. Le passage important est le paragraphe avec RewriteEngine, ProxyPass et ProxyPassReverse – ainsi que le <Proxy *> :
<VirtualHost *:443>
ServerName genealogie.mafamille.org
ServerAdmin admin@mafamille.org
DocumentRoot /home/moi/www/www.mafamille.org/
CustomLog /home/moi/logs/apache2/mafamille.org/access.log combined
RewriteEngine On
ProxyPass / http://serveur.mafamille.com:2317/
ProxyPassReverse / http://serveur.mafamille.com:2317/
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
SSLEngine on
SSLCACertificateFile /etc/apache2/ssl/certs.pem
SSLCertificateFile /etc/apache2/ssl/apache2.pem
SSLCertificateKeyFile /etc/apache2/ssl/apache2.key
SSLProtocol all
SSLCipherSuite HIGH:MEDIUM
<directory /home/jim/www/www.mafamille.org/>
Options None
AllowOverride None
Order Deny,Allow
Allow from all
</directory>
</VirtualHost>
J’ai décidé d’installer QGIS 2.14 (GIS système d’information géographique) sur une Ubuntu, plus par curiosité que par besoin. Si site officiel est riche en documentations, je ne les trouve pas toujours très explicites. Une fois installé, j’ai pu commencer à tester en m’appuyant sur la documentation… Sauf lorsque j’ai voulu importer une cartographie avec des extensions propriétaires, la documentation ne m’a été d’aucune aide. Les options proposées dans l’aide n’y sont pas, où peut-être sont-elles ailleurs, où peut-être la documentation est basée sur version antérieure sans tenir compte de l’évolution…
Bref, voici comment installer le plus simplement possible QGIS 2.14 sur une Ubuntu. Si je persévère, je ferai, peut-être, d’autres tuto sur le sujet ! Cliquer sur lire la suite pour le tutoriel.
Pour commencer, on rajoute les dépôts dans le fichier sources.list
sudo nano /etc/apt/sources.list
Ajoutez les lignes suivantes, bien entendu, si vous avez une Ubuntu « Precise », vous remplacez « trusty » par « precise »
Puis pour mettre à jour les infos sur les paquets.
sudo apt-get update
Si vous avez le message d’erreur ci-dessous, pas de panique…
W: Erreur de GPG : http://qgis.org trusty InRelease : Les signatures suivantes n'ont pas pu être vérifiées car la clé publique n'est pas disponible : NO_PUBKEY 3FF5FFCAD71472C4
Il suffit de vérifier la clé publique dont le n° ici est 3FF5FFCAD71472C4.
W: Erreur de GPG : http://ppa.launchpad.net trusty InRelease : Les signatures suivantes n'ont pas pu être vérifiées car la clé publique n'est pas disponible : NO_PUBKEY 089EBE08314DF160
QGIS est installé, il n’y a plus qu’à en explorer les nombreuses possibilités. Pour cela, QGIS propose un jeu de données « Alaska » inclut toutes les données SIG qui sont utilisées comme exemple et comme aperçus dans le guide de l’utilisateur, mais aussi une petite base de données GRASS ainsi que des exercices…
Geneweb est un logiciel de généalogie, ou plus précisément un serveur de généalogie.
Il s’agit d’un logiciel libre multi-plateforme (linux, bsd, windows, Mac Os X), on y accède via une interface web. On peut l’utiliser en mono poste (localhost) ou l’installer sur un serveur.
Je parle ici de geneweb sous serveur linux, pour ceux sous pc windows, j’imagine que ce doit se faire via mode graphique.
Sur un serveur, deux possibilités d’installation :
soit comme un traditionnel site web avec un script cgi.bin accessible via www.nom_du_serveur.fr/votre_cgi.bin/
soit en service, il est dans ce cas accessible via www.nom_du_serveur.fr:2317/
Vous pouvez démarrer en partant d’un fichier gedcom ou en partant de zéro.
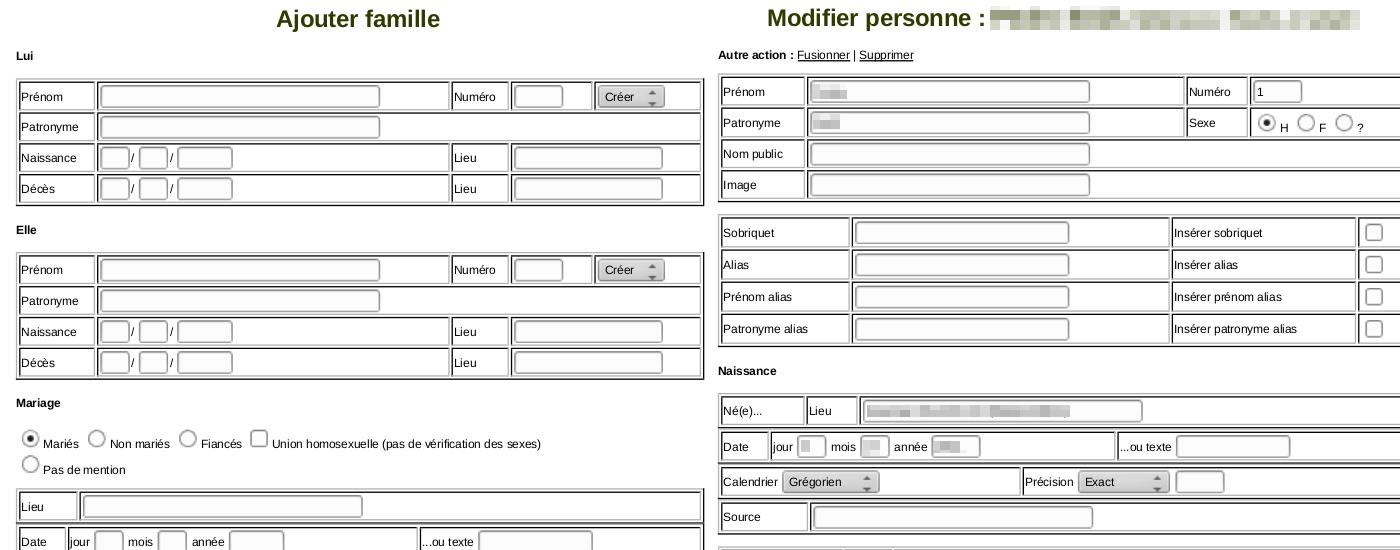
La création de famille, l’enrichissement de l’arbre se fait simplement en remplissant des champs comme sur l’exemple de saisie ci-dessous :
Interface de saisie du logiciel de généalogie Geneweb – Ajout de famille et modification d’une personne.
Les points forts de GeneWeb sont les suivants Interface Web
Affichage dynamique
Calculs de parenté et de consanguinité
Polyglotte
Correction d’orthographe
Titres de noblesse
Mise à jour et protection des informations
Personnalisation (couleur de fond, etc)
Importation et exportation de fichiers GEDCOM
Autres : Historique des mises à jour, Dictionnaire des lieux, Chronique familiale, Forum de la base de données, Statistiques, Anniversaires, Calendriers
Pour certaines tâches spécifiques, si vous avez directement la main sur votre serveur, qu’il est muni d’une interface graphique, d’un écran et un clavier, vous y accéderez par le port 2316 www.localhost:2316/
Si votre serveur est hébergé ou comme moi, n’a pas de clavier, ni écran, ni interface graphique… se sera la ligne de commande.
Amélioration, maintenance.
Le fichier avec l’extension « .gwf » contient la configuration pour une base de données. Si votre arbre s’appelle trucmuche son fichier de configuration sera « trucmuche.gwf ».
Vous y trouvez entre autres le chemin du dossier dans lequel vous souhaitez que vos images soient chargées ainsi que les mots de passe Ami (mode lecture) et Magicien (administrateur)
Spécifier des utilisateurs Amis et Magiciens
Créez 2 fichiers texte avec votre éditeur préféré, le nom et l’extension n’ont pas d’importance, du moins sous linux car je suppose que sous windows l’extension doit avoir son importance, à confimer…
Prenons pour exemple « amitrucmuche.auth » et « magitrucmuche.auth »
Dans le premier, vous mettez « les_noms_amis:mot_de_passe » et sauvegardez dans le même dossier ou se trouve trucmuche.gwf, dans le second, vous faites la même chose avec « les_noms_admin:mot_de_passe ».
Exemple :
Vérifier que « machintruc » est correct et s’il l’est, vous pouvez supprimer trucmuche.gwf, trucmuche.gwo (qui vient d’être créé) et trucmuche.gw (sauf si vous souhaitez le garder comme sauvegarde)
rm -Rf trucmuche.gwf trucmuche.gwo trucmuche.gw
Puis renommer machintruc
mv machintruc.gwb trucmumuche.gwb
Sauvegarder
gwu trucmumuche > trucmumuche.gw
Restaurer
gwc trucmumuche.gw -o trucmumuche
Importer un GEDCOM
ged2gwb trucmuche.ged -o trucmuche
Exporter ver un GEDCOM
gwb2ged trucmuche [options]
Le man pour les options (avec ma modeste traduction)
man gwb2ged
-help aide de ligne de commande
-o <ged>
Nom du fichier de sortie (par défaut: a.ged)
-charset [ASCII | ANSEL]:
Set charset. Par défaut est ASCII. Attention: la valeur ANSEL fonctionne correctement que sur iso-8859-1 bases de données codées.
-o <ged>
Nom du fichier de sortie (par défaut: a.ged)
-mem économiser de l'espace mémoire, mais plus lent
-a <1st_name> [num] <nom>
sélectionnez les ancêtres de
-d <1st_name> [num] <nom>
sélectionnez les descendants de
-aws <1st_name> [num] <nom>
sélectionnez les ancêtres de... avec les frères et sœurs
-s <nom>
sélectionnez ce patronyme (option utilisable plusieurs fois)
-nsp pas les parents ni conjoints (pour les options -s et -d)
-nn aucune note (base de données)
-c <num>
Quand une personne est né il ya moins de <num> années, elle n'est pas exportée sauf si elle est publique. Tous les conjoints et descendants sont également censurés.
Voilà de quoi bien avancer en généalogie avec Geneweb.
LeoCAD (CAD, Computer-aided design) est un programme de conception assistée par ordinateur (CAO), multiplate-forme et sous la licence libre GPL, qui permet de créer des modèles de constructions de type légo de façon intuitive, et très rapidement.
Le programme utilise la collection impressionnante d’outils fourni par la bibliothèque de LDraw et ses plus de 6000 pièces au total, qui permet de commencer la réalisation de formes avec de simples mouvements de glissé / lâché.
L’interface du programme permet de sélectionner différentes parties, attribuer des couleurs, faire pivoter, accéder à différents modes d’affichage (caméras) pour afficher le modèle créé sous tous ses angles et positions possibles, remplir différentes zones de couleurs , diviser l’écran verticalement ou horizontalement et exporter les projets dans différents formats : 3DS, Brick Link, CSV, HTML, POV-Ray y Wavefront.
C’est précisément la capacité d’exporter vers ce dernier type de fichier appelé Wavefront (OBJ), qui le rend si intéressant pour tous ceux qui ont une imprimante 3D et souhaitent imprimer les différentes briques ou modèles créés.
Sur le site LeoCAD, vous trouverez plusieurs tutoriels pour vous lancer dans cette application qui est disponible pour Windows, OS X et Linux.
Installation
Maintenant, nous allons voir comment l’installer dans certains des principaux GNU / Linux :
Sur openSUSE
Dans mon cas pour gecko distro, installé directement à partir des paquets de services de recherche par l’habituel 1 click install
Arch Linux et dérivés comme Manjaro, Antergos ou ArchBang depuis les dépôts de la communauté en exécutant :
yaourt -S leocad
Debian et dérivés comme Ubuntu, linux Mint, etc. depuis une console
Brewtarget – Logiciel de brassage gratuit et Open-Source
Pour linux (bien sûr), Windows et Mac 64-bit Plus bas, liens de téléchargement.
Les brasseurs amateurs et pro vont apprécier, s’ils ne connaissent pas déjà Brewtarget.
Cette application permet de reproduire des recettes existantes ou de vous en inspirer pour créer rapidement vos propres recettes de bières en vous basant sur un style de bière vous que souhaitez brasser.
La prise en main est facile et les possibilités de recettes jusqu’à l’infini.
Les débutants pourront tester les recettes telle quelle, puis peu à peu, varier l’existant.
Les confirmés pourront configurer leur équipement utilisé, ajuster les styles existants et en créer, utiliser les listes de produits fermentescibles, de levures, de houblons, voire enrichir ces listes et/ou les modifier. Il existe aussi une liste « Autres » concernant les ingrédients complémentaires, aussi modifiables.
Bref, une application très très complète que les brasseurs en herbes ou confirmés apprécieront.
Logiciel testé sur xubuntu 14.04, désolé, je n’ai ni windows ni Mac, mais ça ne doit pas beaucoup varier.
J’ai fait une première installation depuis les dépôts.
Sudo atp-get install bewtarget
Cela installe une version traduite à 10 %, et encore, je suis généreux.
Après l’avoir désinstallée, je suis passé par les PPA.
je suis tombé sur cette application par hasard alors que je cherchais tout autre chose. Je dédicace ce billet à TT, à qui j’ai pensé lors de cette découverte.